Multimodal
[Paper Review] Android in the Zoo: Chain-of-Action-Thought for GUI Agents (AITZ)
maotter
2024. 12. 31. 13:00
paper: Zhang, Jiwen, et al. "Android in the zoo: Chain-of-action-thought for gui agents." arXiv preprint arXiv:2403.02713 (2024)
link: https://arxiv.org/abs/2403.02713
Android in the Zoo: Chain-of-Action-Thought for GUI Agents
Large language model (LLM) leads to a surge of autonomous GUI agents for smartphone, which completes a task triggered by natural language through predicting a sequence of actions of API. Even though the task highly relies on past actions and visual observa
arxiv.org
[Abstract]
- 현재 GUI agent 연구들은 task를 달성하기 위해 이전의 행동들이나 시각적 정보들이 중요함에도 현재 스크린샷 이미지나 동작에만 집중하는 한계를 보임
- 본 논문에서 Chain-of-Action-Thought(CoAT) 방법론을 제시함
- 또한 Android-In-The-Zoo (AITZ)라는 AITW 기반의 coat annotation이 되어있는 데이터셋을 공개함
1. Introduction
- 기존의 GUI Agent 연구들은 스마트폰의 다양한 액션들 아래에 깔려있는 Logic보다는 동작의 좌표 값에 집중해왔음
- 본 논문에서는 screen description, next action에 대한 thinking progress, next action description, possible action outcome들을 포함하는 CoAT 방법을 제시함
- CoAT 방법을 활용하여 GPT-4V, Gemini-Pro-Vision, Qwen-VL-Max에서 많은 성능 향상을 보임
- 또한 CoAT annotation이 되어있는 AITZ 데이터셋을 구축하고 이전의 GUI Agent 모델들을 학습시켜서 많은 성능 향상을 보임
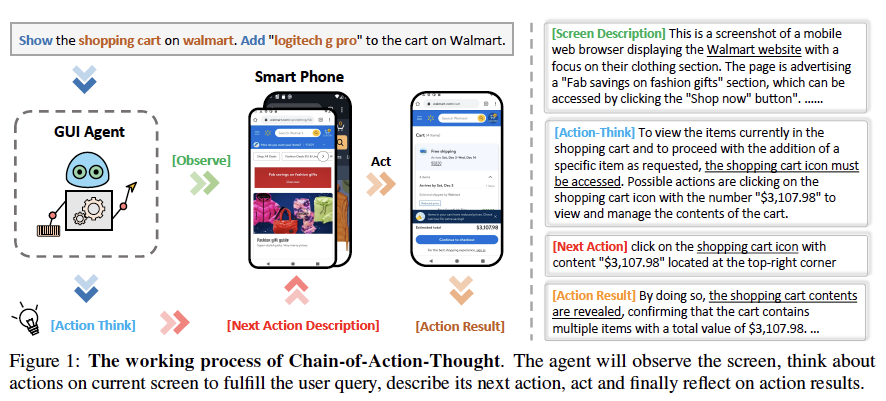
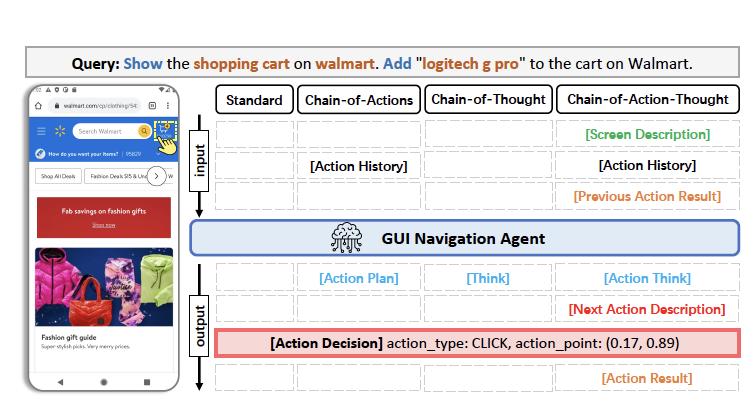
2. Chain-of-Action-Thought (CoAT)
2.1. Definition
- ${\pi}(a_{t}|o_{t},h_{t-1},u)$ where $h_{t-1}=(o_{1},a_{1},...,o_{t-1}.a_{t-1})$
- components of CoAT
- Screen Description
- 주어진 스크린샷의 main content
- screen type,primary apps or widgets 등등..
- decision-making을 위한 textual context를 제공함
- Action Think
- user query와 current action과 history information을 합쳐서 생각하여 task 달성을 위한 possible action들을 떠올림
- Next Action Description
- 동작시킬 UI element나 screen function
- ex. click on the shopping cart icon / scroll up to open the app drawer
- Action Result
- 이전 screenshot과 다음 screenshot을 비교하여 action 결과를 예측함
- Screen Description
2.2 Comparison
- CoT, CoA, CoAT를 비교하기 위해 GPT-4V, Gemini-Pro-Vision, Qwen-VL-Max 모델들로 실험을 진행함
- 데이터셋으로는 AITW에서 랜덤 샘플한 50개의 에피소드를 이용
- 공정한 비교를 위해서 set-of-mark 방법으로 screen의 UI element들을 annotate함
- Result: accuracy에 있어서 CoAT를 사용했을 때 성능 향상이 있음
3. Android in the Zoo (AITZ)
3.1. Data collection
- Instruction sampling
- 기존 AITW에는 instruction과 observation 간의 불일치가 많음
- subset마다 instruction을 기준으로 샘플링하여 중복을 제거하고 error case들을 필터링함
- human annotator로 맞는지 verification
- Semantic Annotation
- Azure-API를 활용한 GPT-4V로 screen description, action thinking, next action description, action result summarization을 하도록 함.
- 이 때 icon detection model 또한 이용함
- 기존의 'DUAL POINT'를 'CLICK'과 'SCROLL'로 나눔
- 이후에 세 명의 Exper로 검증하고 잘못된 부분이 있다면 수정하도록 함. GPT-4V에게 regenerate시킴
- Azure-API를 활용한 GPT-4V로 screen description, action thinking, next action description, action result summarization을 하도록 함.
3.2. Dataset Analysis

4. Experimental Setup
4.1. Baseline Models
- CogAgent
- Auto-UI
4.2. Evaluation Metrics
- Atomic Metrics : action type과 action detail들이 모두 맞으면 correct라고 봄
- Episodic Metrics : 전체 sequence에서 처음으로 틀린 step의 relative position (ex. 10개의 step에서 2번째 step에서 틀리면 0.2)
4.3. Implementation Details
- random split로 70%는 train, 30%는 test
- lr 1e-4로 10 에포크 훈련
5. Experiments
5.1. Zero-Shot Evaluation
- action think prompt를 추가한 CogAgent는 성능 향상을 보임
- 작은 모델인 Auto-UI-base도 CoAT 방법을 적용하자 성능 향상을 보임
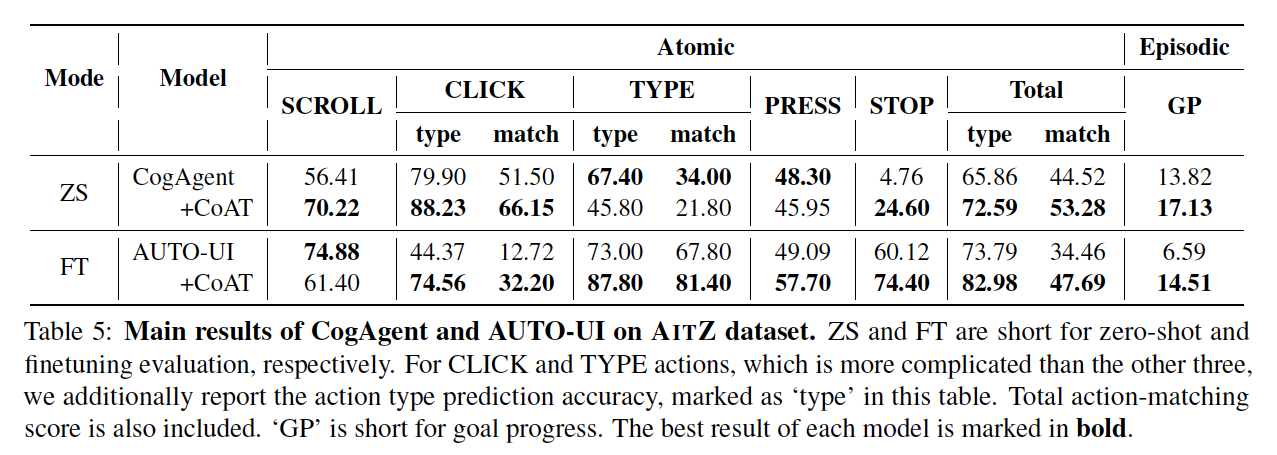
5.2. Fine-tuning Evaluation
- Auto-UI를 Fine-tuning하여 실험해봄
- input에는 screen description과 previous action results가 들어감
- output에는 action think와 action description이 들어감
- 특히 Previous action result와 action think, action description이 결합되었을 때 큰 성능 향상을 보임
- 그러나 Screen description이 추가되었을 때, atomic metrics와 episodic metrics 모두 감소함
- 저자들은 Auto-UI에서 사용되는 visual encoder의 low resolution 문제인 것 같다고 추정함
5.3. Qualitative Analysis
- Auto-UI: CoA에서 action history는 해석되기 어려웠지만 CoAT는 Previous Action Result를 Words로 전달하여 해석하기 쉬움
- CogAgent: Action think를 추가하여 shortcut 제공